Entienda los pros y contras: ETL vs ELT
Los enfoques ETL y ELT representan los 2 métodos tradicionales para la integración de datos. Ambos enfoques incluyen los mismos 3 pasos. La diferencia es el orden en que se realizan. Los 3 pasos son:
- Extract (Extraer): Este paso siempre es la primera tarea. Implica extraer datos estructurados y no estructurados de todos sus sistemas de origen, incluidos SaaS, web sites, datos locales etc. Una vez extraídos los datos, se trasladan al llamado stage area.
- Transform (Transformar): en este paso, los datos se limpian, procesan y transforman en un formato común, de modo que puedan ser consumidos por el destino (por ejemplo, almacén de datos, data lake o base de datos).
- Load (Carga): este paso implica cargar los datos formateados en el sistema de destino. A partir de ahí, los datos están listos para ser analizados.
ETL
ETL (Extract, Transform, Load) ha sido el enfoque estándar para recopilar, reformar e integrar datos durante décadas. Hoy en día, las empresas que necesitan sincronizar diferentes entornos de datos y migrar datos de sistemas heredados utilizan tareas ETL.
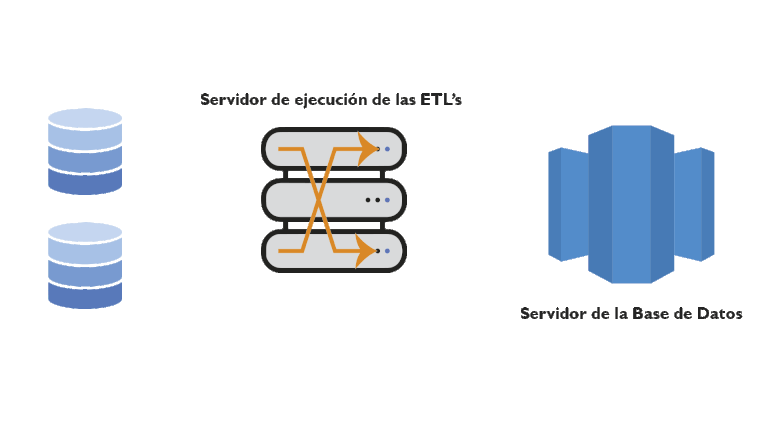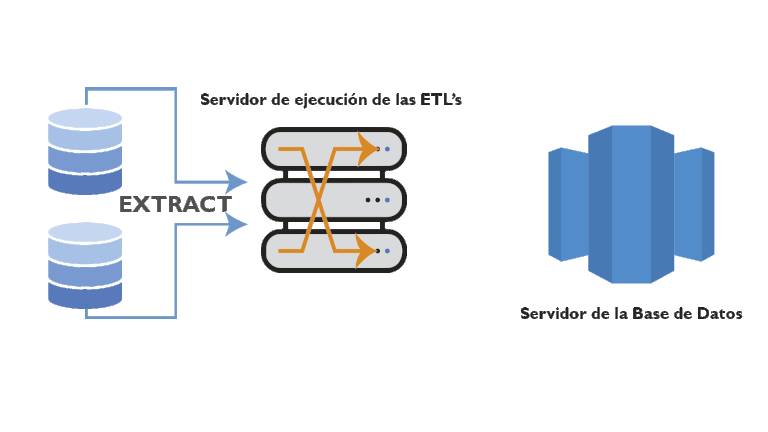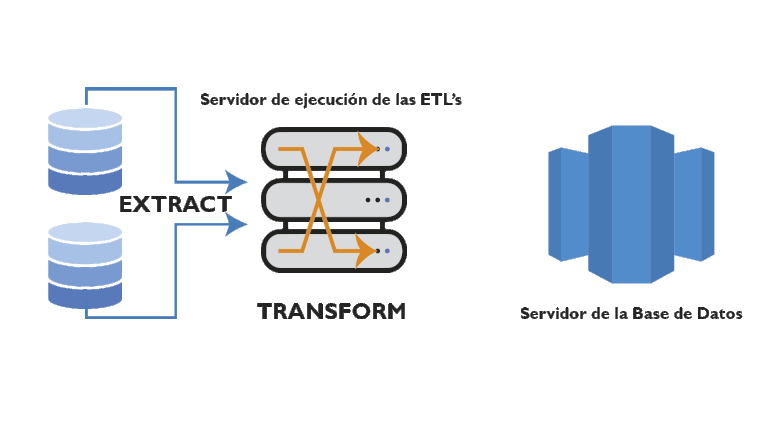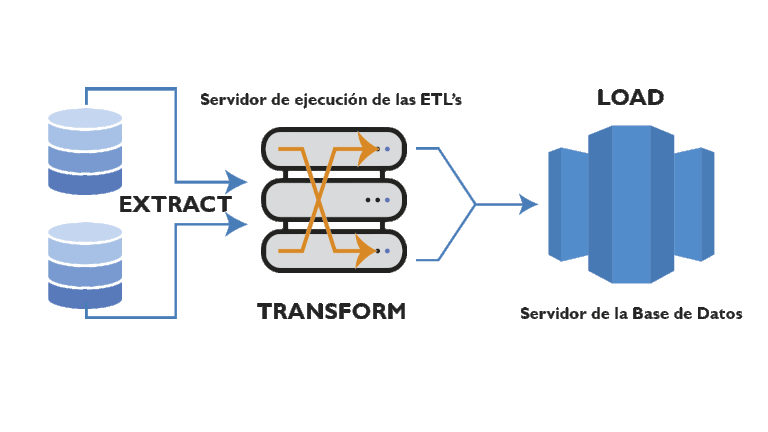
Según se puede apreciar en el esquema anterior la transformación de la información la realiza una herramienta ETL en un servidor de ejecución de ETL’s, normalmente se utiliza una herramienta especializada en estas tareas, aunque realmente se podría utilizar un lenguaje de programación. Esta forma de trabajar, hace que se libere de procesamiento a la CPU el servidor de la base de datos final, lógico, ya que todo este procesamiento intermedio recae en la CPU del servidor de ejecución de ETL’s.
Dado que transforma los datos antes de cargarlos en el sistema de destino, ETL ayuda a reducir el volumen de datos que se almacenan en el almacén de datos final. También puede enmascarar, eliminar y codificar datos específicos para permitir que las empresas cumplan con las normas de privacidad de datos, como GDPR y CCPA.
Sin embargo, ETL tiene algunas desventajas importantes.
Los procesos ETL tradicionales suelen ser lentos y consumen muchos recursos. A menudo, es necesario esperar a que se completen todas las transformaciones antes de cargar los datos en el destino.
Tampoco son muy flexibles y requieren un mantenimiento continuo. Por ejemplo, si sus fuentes de entrada y formatos cambian, debe configurar estas transformaciones y casos límite con anticipación. Finalmente, definir la lógica comercial y las transformaciones para su proceso ETL generalmente tiene un alto precio.
ELT
ELT (Extract, Load, Transform) es un enfoque más nuevo y ahora muy popular para la integración de datos. Intercambia los pasos segundo y tercero en el proceso de integración, de modo que los datos solo se transforman después de que se cargan en el sistema de destino.

En el proceso ELT, la transformación la realiza directamente el gestor de base de datos (con las operaciones que realiza el gestor de base de datos), por ello, la herramienta ETL únicamente se usa como traductor de operaciones de transformación sobre los datos a sentencias SQL interpretables por el motor donde se envían estas instrucciones.
De esta forma, su tiempo de ejecución será menor que en su versión ETL, y la carga de procesamiento se le traspasa a la CPU de la base de datos.
En un esquema ETL jamás se va a tardar menos en transformar la información que en la propia base de datos del gestor de base de datos, con lo que el rendimiento de este proceso será mayor que en su forma ELT.
Como consecuencia de lo anterior se obtiene que no todas las transformaciones son posibles ELT, o al menos de una forma sencilla y práctica. En otro artículo hablaremos de las transformaciones que encajan en un esquema ETL y no en uno ELT.
El auge de ELT se debe a la ubicuidad del almacenamiento en la nube. Hoy en día, las empresas pueden almacenar cantidades masivas de datos en la nube de manera potente y asequible, de esa manera se utiliza a las bases de datos para realizar las transformaciones. Como resultado, es mucho menos importante filtrar los datos y reducir los volúmenes de datos antes de transferirlos a los sistemas de destino. La otra razón principal por la elección de ELT es porque las tareas de integración de datos no son adecuadas para procesar el creciente volumen de datos no estructurados generados por los sistemas basados en la nube.
Como ya hemos dicho antes diferencia ELT es rápido, flexible y permite una fácil integración de fuentes de datos nuevas o diferentes. Dado que ELT está más automatizado, requiere un mantenimiento mínimo, y debido a la fácil escalabilidad de los servidores de base de datos en cloud, también es más fácilmente.
Sin embargo, ELT también tiene sus propias desventajas.
Primero, todavía es necesario transformar los datos, una vez que se mueven al lago de datos o a cualquier otro almacén de datos de destino. La transformación puede ser costosa, ya que los proveedores de almacenes y lagos de datos cobran a los clientes por procesar datos en el sistema. Además, el esfuerzo necesario para transformar, limpiar y preparar los datos pasó del ingeniero de datos al usuario de datos comerciales o al científico de datos, lo que genera cargas de trabajo adicionales que consumen mucho tiempo y una mayor latencia.
Por otra parte, cargar todos los datos en los sistemas de destino antes de que se transformen da acceso a varios usuarios y aplicaciones a los mismos, lo que crea riesgos de seguridad y dificulta el cumplimiento de las normas de privacidad de datos.
Como hemos visto todo tiene sus pros y contras, lo que sí que proponemos desde Modus es no tener posturas maximalistas de ante mano y ser flexibles para proporcionar la mejor solución técnica ante un determinado proyecto manejando la posibilidad de ambos enfoques.



